Ich habe neulich per AnythingLLM eine Docker Chroma Instanz verwendet.
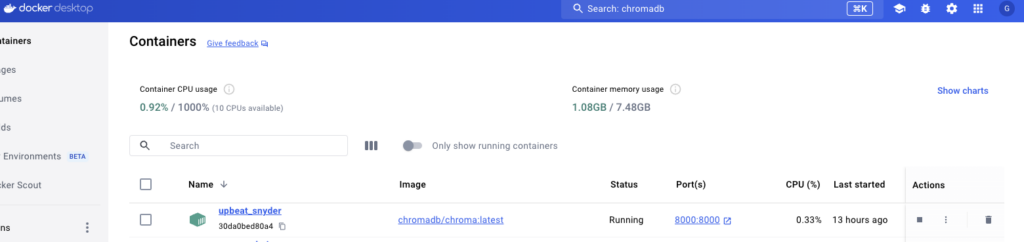
Dazu wollte ich dann Daten abfragen. Das war erst mal nicht ganz so einfach, bis ich die YAML dazu gefunden habe (das YAML ist am Ende dieser Seite bzw unter http://localhost:8000/docs).
Das Ganze sieht in swagger.io formatiert so aus
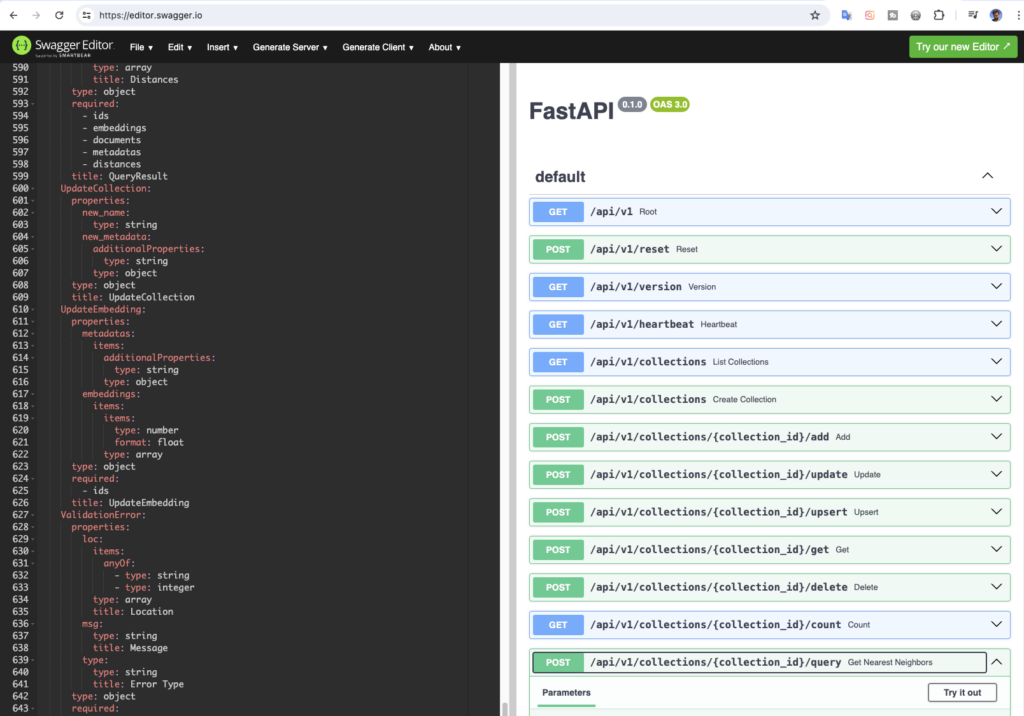
So kannst du die DB Abfragen
Ist die DB überhaupt erreichbar / Heartbeat
http://127.0.0.1:8000/api/v1/heartbeat
Ausgabe irgendwas wie: {„nanosecond heartbeat“:1717134488888233555}
Collections auflisten
http://127.0.0.1:8000/api/v1/collections
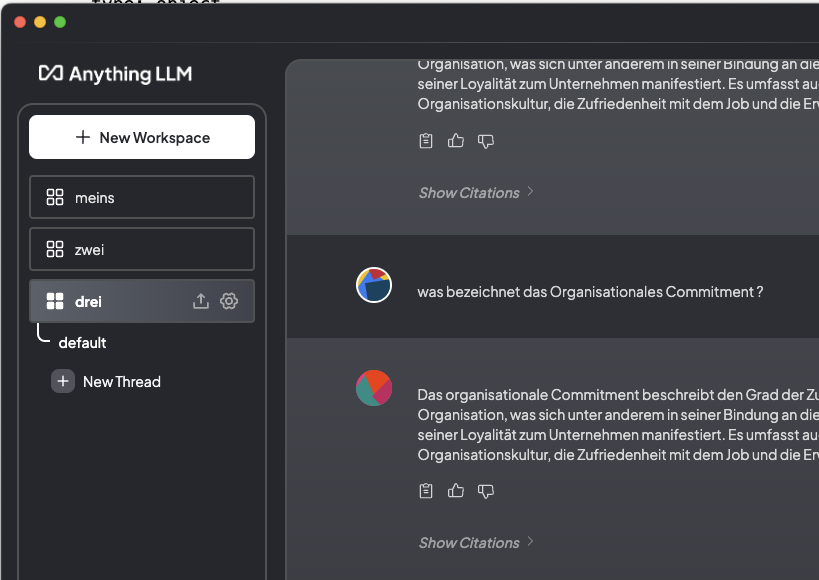
Es findet sich der CollectionName der zum Workspace passt.
Dort habe ich mehrere Dokumente eingestellt
obige URL gibt also die Collections aus, in dem falle die „drei“, also den Namen des Workspaces.. Hätte ich das gewusst, hätte ichs anders benamst 😉

Beim Einfügen von Daten sieht man das übrigens schön in Docker
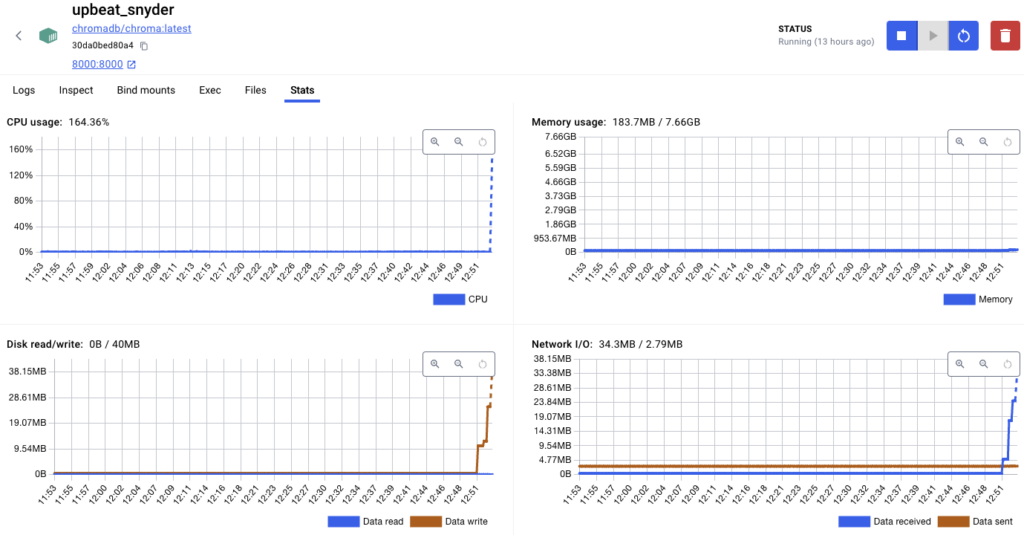
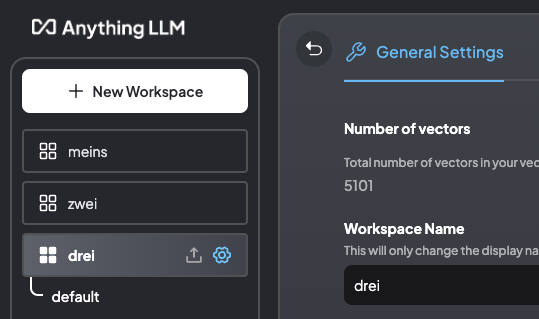
Anzahl der Embeddings auflisten
Dazu nutzen wir die (UU)id von „drei“ (siehe Screenshot vorher)
http://127.0.0.1:8000/api/v1/collections/734cb4ec-0b72-43d0-8e2c-d23680b7b2c8/count
Das entspricht auch der Ausgabe in AnythingLLM
Das Gleiche in python
pip install chromadb-client
ist installiert:
import chromadb
# Example setup of the client to connect to your chroma server
client = chromadb.HttpClient(host='localhost', port=8000)
collection = client.get_collection(name="drei")
print("-----------------------");
print(collection.peek()) # returns a list of the first 10 items in the collection
print("-----------------------");
print(collection.count()) # returns the number of items in the collection
print("-----------------------");
Wie kommen wir nun an die Daten / query?
Dazu müssen wir erst mal verstehen, welches Embedding-Modell genutzt wurde.
AnythingLLM hat im Standard sein „eigenes“ Modell
https://docs.useanything.com/features/embedding-models
und das verweist auf https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
Dann erstellen wir mal einen einfachen python Client dazu:
import chromadb
from chromadb.config import Settings
from transformers import AutoTokenizer, AutoModel
import torch
import json
# Verbinde dich mit der ChromaDB
client = chromadb.HttpClient(host='localhost', port=8000)
# Definiere den Namen der Collection
collection_name = "drei"
# Hole oder erstelle die Collection
collection = client.get_or_create_collection(name=collection_name)
# Lade ein vortrainiertes Modell und Tokenizer von Hugging Face
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
# Definiere eine Einbettungsfunktion
def embed_text(texts):
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
with torch.no_grad():
embeddings = model(**inputs)
return embeddings.last_hidden_state.mean(dim=1).numpy()
# Führe eine Query aus
query_text = ["Frithjof Bergmann"]
query_embeddings = embed_text(query_text)
results = collection.query(
query_embeddings=query_embeddings.tolist(), # Nutze die Einbettungen für die Abfrage
n_results=5
)
print("-----RESULTS-----");
# print(results);
# Formatiert ausgeben
formatted_data = json.dumps(results, indent=4, ensure_ascii=False)
print(formatted_data)
## Zeige die Ergebnisse an
#for result in results:
## print(result)
und klappt:
Zusammenfassung
(Folgende Antworten sind von der KI generiert)
Hier ist ein schematisches Diagramm, das den Aufbau und die Interaktion der Komponenten im beschriebenen System darstellt:
- Einbettungsfunktion: Dies ist der Teil, in dem du mit einem vortrainierten Modell (z.B. von Hugging Face) Texte in numerische Vektoren (Embeddings) umwandelst.
- ChromaDB: Dies ist die Datenbank, die in SQLite gespeichert ist und die Dokumente sowie ihre zugehörigen Embeddings speichert.
- Abfrage: Der Teil, in dem du die Embeddings von Abfragetexten berechnest und diese Embeddings dann zur Abfrage der Datenbank verwendest, um ähnliche Dokumente zu finden.
Erläuterungen:
- Benutzer-Anwendung: Hier beginnt der Prozess. Der Benutzer sendet einen Text (z.B. Dokumente oder Abfragen).
- Einbettungsfunktion: Diese Komponente verwendet ein vortrainiertes Modell, um Texte in Embeddings (numerische Vektoren) zu transformieren.
- Embeddings: Die generierten Embeddings werden entweder in die Datenbank eingefügt (für neue Dokumente) oder für Abfragen verwendet.
- ChromaDB: Eine SQLite-basierte Datenbank, die die Dokumente und ihre Embeddings speichert.
- Abfrageverarbeitung: Bei einer Abfrage werden die Embeddings des Abfragetextes mit den gespeicherten Embeddings in der Datenbank verglichen, um ähnliche Dokumente zu finden.
- Abfrageergebnisse: Die Ergebnisse der Abfrage (ähnliche Dokumente) werden an die Benutzer-Anwendung zurückgegeben.
Wie funktioniert die Abfrage?
1) Wieso muss der Text in einen Vektor eingebettet werden?
In der maschinellen Verarbeitung von Sprache (Natural Language Processing, NLP) sind Maschinen nicht in der Lage, Text direkt zu verstehen. Sie benötigen eine numerische Darstellung des Textes, die sie verarbeiten können. Diese numerische Darstellung wird als „Einbettung“ (Embedding) bezeichnet und ist ein Vektor, der den Text in einem kontinuierlichen Zahlenraum repräsentiert.
Einbettungen haben folgende Vorteile:
- Semantische Ähnlichkeit: Ähnliche Texte erhalten ähnliche Vektoren. Das bedeutet, dass die Abstände zwischen Vektoren semantische Ähnlichkeiten widerspiegeln.
- Effizienz: Vektoroperationen sind effizient und ermöglichen schnelle Berechnungen und Vergleiche.
- Universelle Darstellung: Einbettungen können universell für verschiedene Aufgaben verwendet werden, z.B. für Klassifikation, Clustering oder Suche.
2) Wie formuliere ich den Text richtig? Wird dieser 1:1 gesucht oder sollte man eine Frage stellen oder wie funktioniert das?
Der Text wird nicht 1:1 gesucht wie bei einer einfachen Textsuche, sondern die Einbettung des Textes wird mit den Einbettungen der in der Datenbank gespeicherten Texte verglichen. Daher ist es wichtig, den Text so zu formulieren, dass er den gewünschten Inhalt oder Kontext gut wiedergibt.
Hier sind einige Hinweise zur Formulierung des Textes:
- Klarheit und Präzision: Verwende klare und präzise Formulierungen, um den gewünschten Kontext oder die Bedeutung zu vermitteln.
- Natürliche Sprache: Du kannst den Text in natürlicher Sprache schreiben, da das Einbettungsmodell in der Lage ist, den semantischen Gehalt zu erfassen.
- Fragen stellen: Das Stellen von Fragen kann hilfreich sein, wenn du nach spezifischen Informationen suchst. Zum Beispiel: „Was ist die Philosophie von Frithjof Bergmann?“ anstatt nur „Frithjof Bergmann“.
3) Wird hier das KI-Modell irgendwie genutzt?
Ja, das KI-Modell wird in mehreren Schritten genutzt:
- Text-Einbettung: Das Modell
sentence-transformers/all-MiniLM-L6-v2, das auf der Hugging Face-Plattform bereitgestellt wird, ist ein vortrainiertes Transformationsmodell, das dazu dient, Texte in Vektoren (Einbettungen) umzuwandeln. Hier wird der Text durch den Tokenizer und das Modell verarbeitet, um seine numerische Darstellung zu erhalten. - Ähnlichkeitsabfrage: Die erhaltenen Einbettungen werden dann genutzt, um semantische Ähnlichkeiten zwischen dem Abfragetext und den in der Datenbank gespeicherten Texten zu berechnen. Das KI-Modell hilft dabei, die Bedeutung des Textes zu erfassen und vergleichbare Inhalte in der Datenbank zu finden.
Hier ein genauerer Ablauf:
- Der Text „Frithjof Bergmann“ wird tokenisiert und durch das Modell geführt, das eine Einbettung (Vektor) erstellt.
- Diese Einbettung wird mit den Einbettungen der Texte in der Datenbank verglichen.
- Die Ähnlichkeit wird berechnet, und die am besten passenden Einträge werden zurückgegeben.
Das vortrainierte Modell sorgt dafür, dass die Einbettungen die semantische Bedeutung des Textes widerspiegeln, wodurch ähnliche Inhalte gefunden werden können, selbst wenn die exakten Wörter nicht übereinstimmen.
4) Kann man das nur für Suche nutzen oder könnte man zB zu Fragen so auch Antworten hinterlegen und diese nutzen?
a, du kannst verschiedene Dokumenttypen in der Datenbank hinterlegen und sicherstellen, dass nur bestimmte Typen bei einer Abfrage berücksichtigt werden. Hier sind einige Strategien, wie du dies erreichen kannst:
1. Dokumenttyp kennzeichnen:
Du kannst jedes Dokument mit einem Typ-Tag versehen, z.B. „Frage“ oder „Antwort“. Diese Tags werden bei der Abfrage berücksichtigt, um sicherzustellen, dass nur die relevanten Dokumente zurückgegeben werden.
2. Sammlung in verschiedene Kategorien unterteilen:
Du könntest mehrere Sammlungen erstellen, z.B. eine Sammlung für „Fragen“ und eine andere für „Antworten“. Bei einer Abfrage auf die Sammlung „Antworten“ wird sichergestellt, dass nur Antworten zurückgegeben werden.
3. Filter in der Abfrage verwenden:
Wenn du alle Dokumente in einer einzigen Sammlung behältst, kannst du zusätzliche Metadaten verwenden, um den Typ zu kennzeichnen und dann bei der Abfrage einen Filter anzuwenden.
Beispielimplementierung:
Hier ein Beispiel, wie du die Dokumenttypen in einer ChromaDB-Sammlung kennzeichnen und filtern kannst:
- Dokumente hinzufügen mit Typ-Tag:
# Beispiel-Dokumente hinzufügen documents = [ {"text": "Was ist die Philosophie von Frithjof Bergmann?", "type": "Frage"}, {"text": "Die Philosophie von Frithjof Bergmann betont die Bedeutung der Arbeit.", "type": "Antwort"} ] for doc in documents: embedding = embed_text([doc["text"]]) collection.add({ "text": doc["text"], "type": doc["type"], "embedding": embedding.tolist() })
- Abfrage mit Typ-Filter:
# Beispiel-Abfrage query_text = ["Was ist die Philosophie von Frithjof Bergmann?"] query_embedding = embed_text(query_text) results = collection.query( query_embeddings=query_embedding.tolist(), n_results=5, filter={"type": "Antwort"} # Nur Antworten zurückgeben )print("-----RESULTS-----") formatted_data = json.dumps(results, indent=4, ensure_ascii=False) print(formatted_data)
Erweiterte Filterung:
Falls ChromaDB erweiterte Filterung unterstützt, kannst du auch komplexere Filterkriterien anwenden, um gezielt nach Antworten zu suchen.
Nutzung mehrerer Sammlungen:
Eine alternative Methode besteht darin, separate Sammlungen für Fragen und Antworten zu verwenden. Hier ein Beispiel:
- Erstellen von Sammlungen für Fragen und Antworten:
# Sammlungen erstellen questions_collection = client.get_or_create_collection(name="questions") answers_collection = client.get_or_create_collection(name="answers") # Dokumente hinzufügen questions_collection.add({ "text": "Was ist die Philosophie von Frithjof Bergmann?", "embedding": embed_text(["Was ist die Philosophie von Frithjof Bergmann?"]).tolist() })answers_collection.add({ "text": "Die Philosophie von Frithjof Bergmann betont die Bedeutung der Arbeit.", "embedding": embed_text(["Die Philosophie von Frithjof Bergmann betont die Bedeutung der Arbeit."]).tolist() })
- Abfrage nur in der Antworten-Sammlung:
# Beispiel-Abfrage nur in der Antworten-Sammlung query_text = ["Was ist die Philosophie von Frithjof Bergmann?"] query_embedding = embed_text(query_text) results = answers_collection.query( query_embeddings=query_embedding.tolist(), n_results=5 ) print("-----RESULTS-----") formatted_data = json.dumps(results, indent=4, ensure_ascii=False) print(formatted_data)
Fazit:
Durch das Kennzeichnen von Dokumenttypen und die Anwendung von Filtern bei der Abfrage kannst du sicherstellen, dass nur relevante Dokumente zurückgegeben werden, z.B. nur Antworten auf gestellte Fragen. Dies bietet eine flexible und effektive Methode, um unterschiedliche Dokumenttypen in einer einzigen Datenbank zu verwalten und abzufragen.
Hier das oben erwähnte Yaml für ChromaDB
openapi: 3.0.2
info:
title: FastAPI
version: 0.1.0
paths:
/api/v1:
get:
summary: Root
operationId: root
responses:
'200':
description: Successful Response
content:
application/json:
schema:
additionalProperties:
type: integer
type: object
title: Response Root Api V1 Get
/api/v1/reset:
post:
summary: Reset
operationId: reset
responses:
'200':
description: Successful Response
content:
application/json:
schema:
type: boolean
title: Response Reset Api V1 Reset Post
/api/v1/version:
get:
summary: Version
operationId: version
responses:
'200':
description: Successful Response
content:
application/json:
schema:
type: string
title: Response Version Api V1 Version Get
/api/v1/heartbeat:
get:
summary: Heartbeat
operationId: heartbeat
responses:
'200':
description: Successful Response
content:
application/json:
schema:
additionalProperties:
type: integer
type: object
title: Response Heartbeat Api V1 Heartbeat Get
/api/v1/collections:
get:
summary: List Collections
operationId: list_collections
responses:
'200':
description: Successful Response
content:
application/json:
schema:
items:
$ref: '#/components/schemas/Collection'
type: array
title: Response List Collections Api V1 Collections Get
post:
summary: Create Collection
operationId: create_collection
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/CreateCollection'
required: true
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/Collection'
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
/api/v1/collections/{collection_id}/add:
post:
summary: Add
operationId: add
parameters:
- required: true
schema:
type: string
title: Collection Id
name: collection_id
in: path
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/AddEmbedding'
required: true
responses:
'201':
description: Successful Response
content:
application/json:
schema:
type: boolean
title: Response Add Api V1 Collections Collection Id Add Post
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
/api/v1/collections/{collection_id}/update:
post:
summary: Update
operationId: update
parameters:
- required: true
schema:
type: string
title: Collection Id
name: collection_id
in: path
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/UpdateEmbedding'
required: true
responses:
'200':
description: Successful Response
content:
application/json:
schema:
type: boolean
title: Response Update Api V1 Collections Collection Id Update Post
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
/api/v1/collections/{collection_id}/upsert:
post:
summary: Upsert
operationId: upsert
parameters:
- required: true
schema:
type: string
title: Collection Id
name: collection_id
in: path
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/AddEmbedding'
required: true
responses:
'200':
description: Successful Response
content:
application/json:
schema:
type: boolean
title: Response Upsert Api V1 Collections Collection Id Upsert Post
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
/api/v1/collections/{collection_id}/get:
post:
summary: Get
operationId: get
parameters:
- required: true
schema:
type: string
title: Collection Id
name: collection_id
in: path
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/GetEmbedding'
required: true
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/GetResult'
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
/api/v1/collections/{collection_id}/delete:
post:
summary: Delete
operationId: delete
parameters:
- required: true
schema:
type: string
title: Collection Id
name: collection_id
in: path
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/DeleteEmbedding'
required: true
responses:
'200':
description: Successful Response
content:
application/json:
schema:
items:
type: string
format: uuid
type: array
title: Response Delete Api V1 Collections Collection Id Delete Post
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
/api/v1/collections/{collection_id}/count:
get:
summary: Count
operationId: count
parameters:
- required: true
schema:
type: string
title: Collection Id
name: collection_id
in: path
responses:
'200':
description: Successful Response
content:
application/json:
schema:
type: integer
title: Response Count Api V1 Collections Collection Id Count Get
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
/api/v1/collections/{collection_id}/query:
post:
summary: Get Nearest Neighbors
operationId: get_nearest_neighbors
parameters:
- required: true
schema:
type: string
title: Collection Id
name: collection_id
in: path
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/QueryEmbedding'
required: true
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/QueryResult'
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
/api/v1/collections/{collection_name}:
get:
summary: Get Collection
operationId: get_collection
parameters:
- required: true
schema:
type: string
title: Collection Name
name: collection_name
in: path
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/Collection'
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
delete:
summary: Delete Collection
operationId: delete_collection
parameters:
- required: true
schema:
type: string
title: Collection Name
name: collection_name
in: path
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/Collection'
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
/api/v1/collections/{collection_id}:
put:
summary: Update Collection
operationId: update_collection
parameters:
- required: true
schema:
type: string
title: Collection Id
name: collection_id
in: path
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/UpdateCollection'
required: true
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/Collection'
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
components:
schemas:
AddEmbedding:
properties:
metadatas:
items:
additionalProperties:
type: string
type: object
embeddings:
items:
items:
type: number
format: float
type: array
type: object
required:
- ids
title: AddEmbedding
Collection:
properties:
name:
type: string
id:
type: string
format: uuid
metadatas:
additionalProperties:
type: string
type: object
type: object
required:
- name
- id
title: Collection
CreateCollection:
properties:
metadata:
additionalProperties:
type: string
type: object
type: object
required:
- name
title: CreateCollection
DeleteEmbedding:
properties:
ids:
items:
type: string
type: array
where:
additionalProperties:
type: string
type: object
where_document:
additionalProperties:
type: string
type: object
type: object
title: DeleteEmbedding
GetEmbedding:
properties:
ids:
items:
type: string
type: array
limit:
type: integer
offset:
type: integer
sort:
type: string
where:
additionalProperties:
type: string
type: object
where_document:
additionalProperties:
type: string
type: object
type: object
title: GetEmbedding
GetResult:
properties:
ids:
items:
type: string
type: array
title: Ids
embeddings:
items:
anyOf:
- items:
type: number
type: array
- items:
type: integer
type: array
type: array
title: Embeddings
documents:
items:
type: string
type: array
title: Documents
metadatas:
items:
additionalProperties:
anyOf:
- type: string
- type: integer
- type: number
- type: boolean
type: object
type: array
title: Metadatas
type: object
required:
- ids
- embeddings
- documents
- metadatas
title: GetResult
HTTPValidationError:
properties:
detail:
items:
$ref: '#/components/schemas/ValidationError'
type: array
title: Detail
type: object
title: HTTPValidationError
QueryEmbedding:
properties:
where:
additionalProperties:
type: string
type: object
where_document:
additionalProperties:
type: string
type: object
query_embeddings:
items:
items:
type: number
format: float
type: array
type: array
n_results:
type: integer
include:
items:
type: string
type: array
type: object
required:
- query_embeddings
title: QueryEmbedding
QueryResult:
properties:
ids:
items:
items:
type: string
type: array
type: array
title: Ids
embeddings:
items:
items:
anyOf:
- items:
type: number
type: array
- items:
type: integer
type: array
type: array
type: array
title: Embeddings
documents:
items:
items:
type: string
type: array
type: array
title: Documents
metadatas:
items:
items:
additionalProperties:
anyOf:
- type: string
- type: integer
- type: number
- type: boolean
type: object
type: array
type: array
title: Metadatas
distances:
items:
items:
type: number
type: array
type: array
title: Distances
type: object
required:
- ids
- embeddings
- documents
- metadatas
- distances
title: QueryResult
UpdateCollection:
properties:
new_name:
type: string
new_metadata:
additionalProperties:
type: string
type: object
type: object
title: UpdateCollection
UpdateEmbedding:
properties:
metadatas:
items:
additionalProperties:
type: string
type: object
embeddings:
items:
items:
type: number
format: float
type: array
type: object
required:
- ids
title: UpdateEmbedding
ValidationError:
properties:
loc:
items:
anyOf:
- type: string
- type: integer
type: array
title: Location
msg:
type: string
title: Message
type:
type: string
title: Error Type
type: object
required:
- loc
- msg
- type
title: ValidationError